
Introduction
Language has always been difficult for computers to understand, and one of the major reasons for this is the need for a more basic language context. Each NLP task can be solved by using an individual model created for each task.
In 2018, Google released a paper, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, which aimed to pre-train a model so that it can easily be fine-tuned by adding layers to create a state-of-the-art model for various tasks like question-answering and language-inference without substantial task-specific architecture modification.
In this article, we will see the model that revolutionized the NLP space and understand how it will work.
WHAT IS BERT?
BERT is an open-source machine learning framework to understand natural language better. BERT stands for Bidirectional Encoder Representation from Transformer; as the name suggests, BERT is based on Transformer architecture, which uses the encoder representation to learn the context/information from both the left and right side of the token during the training phase. That’s why it is called bidirectional or unidirectional.
Let’s see, with an example, how bi-directionality helps in understanding the meaning of the language:
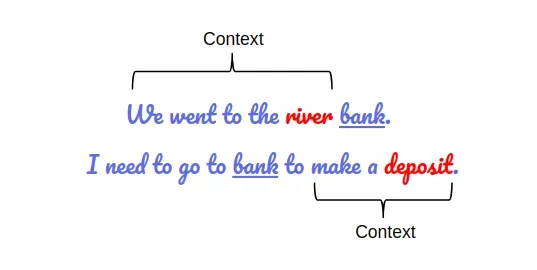
As we can see in the above example, the word ‘bank’ has a different meaning in both sentences. So if the model does not consider context from both sides, it will make a mistake in at least one of the sentences.
Why do we need BERT?
The major limitation of models until BERT is that they are unidirectional, which limits the choice of architecture that can be used during the pre-training.
For example, one of the famous models, GPT uses left-to-right architecture, where every token has access to the previous token.
How does BERT work?
To gain a better understanding of how BERT works, we will see the following:
- Model Architecture - In this, we will see the architecture of BERT, which is a Transformer
- Text Preprocessing/Embedding - It explains how BERT takes words as input and can convert them into vectors.
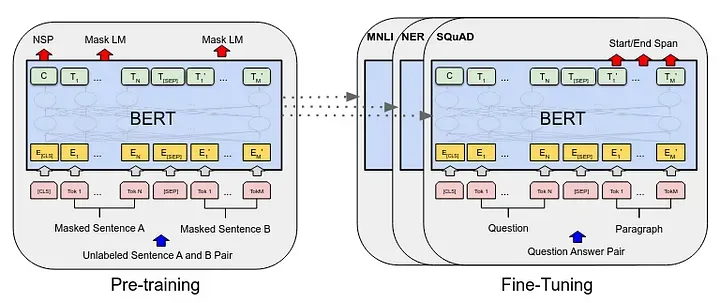
- Training - BERT is trained through a two-stage process: pre-training and fine-tuning.
Model Architecture
The BERT architecture builds on the top of the transformer. All the transformer blocks present in the BERT model are encoder-only. In an initial release, it has 2 variants:
- BERT Base: 12 layers (transformer block), 12 attention heads, and 110M parameter
- BERT Large: 24 layers (transformer block), 16 attention heads, and 340M parameter
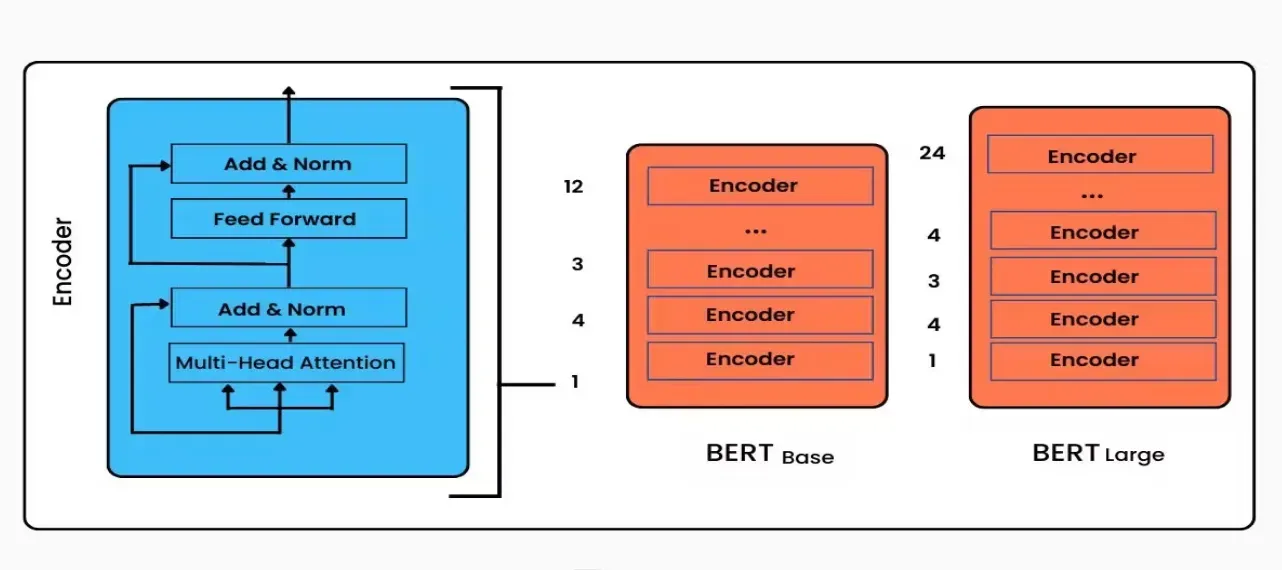
credit: https://www.turing.com/kb/how-bert-nlp-optimization-model-works
Embedding
We cannot provide words to the model, we first convert words into vectors, and this process is called embedding. In BERT, there are three types of embedding for converting words into numerical representation vectors as discussed below:
- Position Embedding: as in BERT or transformer, we don’t pass the data sequentially, so we use position embedding to indicate the position of each token in the sequence. This is the same as we have seen in the transformer paper.
- Segment Embedding: as BERT also takes sentence pairs as input for various tasks, segment embedding is added to every token, indicating whether it belongs to sentence A or B. This allows the encoder to distinguish between the sentences.
- Token Embedding: A [CLS] token is added to the input word tokens at the beginning of the first sentence, and a [SEP] token is inserted at the end of each token.
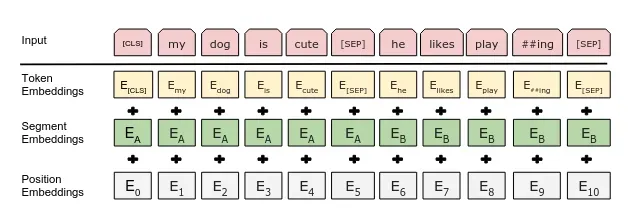
For a given token, its input representation is constructed by summing the corresponding position embedding, segment embedding, and token embedding.
Training
BERT is trained through a two-stage process: pre-training and fine-tuning. Pre-training involves training on a large corpus of unlabeled text data using MLM and NSP objectives, enabling BERT to learn contextualized word representations.
Fine-tuning then adapts the pre-trained BERT model to specific downstream tasks using task-specific labeled data, optimizing task-specific loss functions. This combination of pre-training and fine-tuning allows BERT to excel in understanding and solving a wide range of NLP problems.
Pre-Training
When training language models, there is a challenge of defining a prediction goal. Many models predict the next word in a sequence (e.g., “The child came home from ___”), a directional approach that inherently limits context learning. To overcome this challenge, BERT uses two training strategies: MaskedLM (MLM) and Next Sentence Prediction (NSP).
Masked LM (MLM)
It’s an unsupervised technique for training a model, MLM replaces some percentage of the input token with the [MASK] token, and the model then attempts to predict the original value of the masked token based on the context provided by the word in the sequences as also described by the image below.
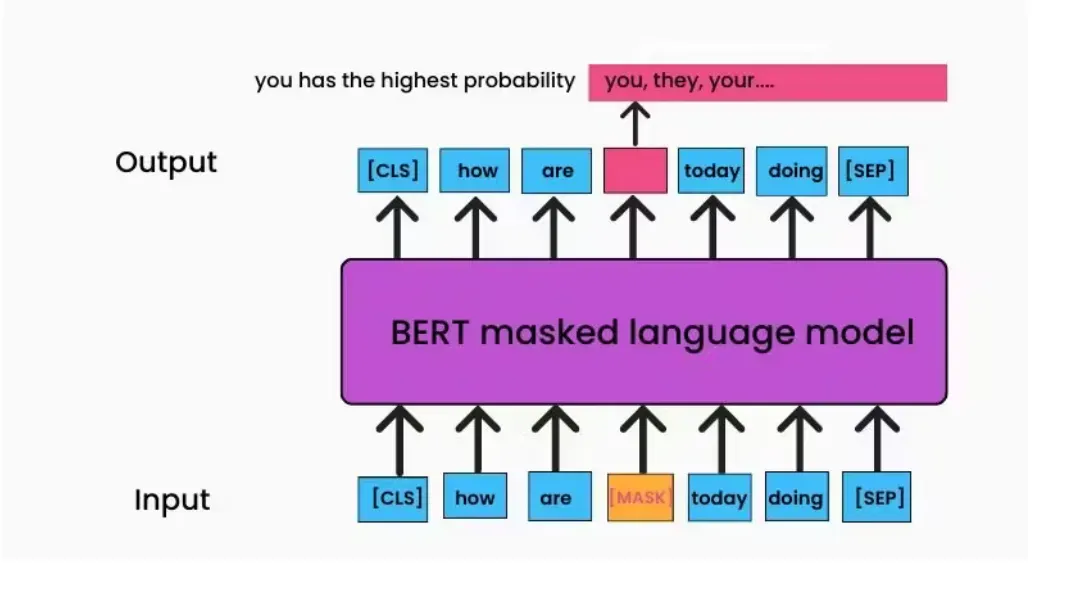 https://www.turing.com/kb/how-bert-nlp-optimization-model-works
https://www.turing.com/kb/how-bert-nlp-optimization-model-works
Major takeaways in MLM:
- The BERT loss function considers only the prediction of the masked values and ignores the non-masked words.
- As MLM only makes predictions on 15% of the token in every batch, compared to standard language model training, it requires more pre-training steps to converge.
- After getting an output from the encoder, it will multiply it by embedding a matrix to transform it into a vocabulary dimension and calculate the probability of each word using Softmax.
- In the paper, the author replaces words with [MASK] 80% of the time. In 10% of cases, the word is replaced with a random word, and in another 10%, the original word remains unchanged. This approach ensures that the encoder cannot determine which word model needs to be predicted or which has been randomly replaced. As a result, a distributional contextual representation of every token is maintained.
Next Sentence Prediction (NSP)
During MLM, the relationship between sentences also plays a significant role in tasks like question answering, so we use NSP to train a model that understands this relationship.
During the training phase, we choose a pair of sentences as input and learn to predict if the second sentence in the pair is the subsequent sentence in the original document.

During training, we choose inputs such that 50% of the inputs are a pair, a subsequent sentence in the original document labeled isNext, while the other 50% are random sentences from the corpus labeled ‘Not Next’. This converts into a classification problem with 2 labels.
We simply compute the input sequences, which go through a transformer-based model, and the output of the [CLS] token is transformed into a 2*1 vector using a simple classification layer, and a label is assigned using Softmax. The model is trained with both MLM and NSP together, to minimize the combined loss function from both strategies.
Fine Tuning
After pre-training, BERT is fine-tuned on specific tasks using the labeled data. In fine-tuning training, most hyperparameters remain the same as in BERT training.
The goal of fine-tuning is to optimize the BERT model to perform well on a specific task by adjusting its parameters to better fit the data. For example, a BERT model pre-trained on a large corpus of text data can be fine-tuned on a smaller dataset of movie reviews to improve its ability to accurately predict the sentiment of a given review.
Conclusion:
By implementing bidirectional training, BERT has transformed natural language processing and enabled models to comprehend words in their complete context. BERT, which is based on the Transformer architecture, outperforms earlier unidirectional models in a variety of NLP tasks. It has raised the bar for NLP performance since it can be pre-trained on big datasets and adjusted for certain jobs without requiring significant architectural changes. Because of its adaptability and efficiency, BERT has become a fundamental model that is changing how computers understand and process human language.