
In recent years, large language models (LLMs) have become popular for their ability to generate text that sounds human-like. They’re used in many areas, like writing articles and helping with customer service. However, despite their impressive performance, they also have significant shortcomings. One major issue is their tendency to produce hallucinations, which will be discussed ahead in the blog. To tackle these issues, researchers have come up with a method called Retrieval-Augmented Generation (RAG)
RAG enhances the performance of LLMs by allowing them to pull in relevant information from external sources before generating a response. In this blog, we will explore the latest trends in LLMs, discuss their shortcomings, and dive deeper into how RAG can provide a more reliable and effective approach to natural language generation.
Problem in LLM:
- Hallucination: In the context of large language models, “hallucination” means that the model creates information that sounds good but is wrong or makes no sense. It’s like when someone confidently tells a story that’s not true at all, even though it sounds believable. As we see in the below image, the model is not able to understand the twist in question, as before this riddle, some standard riddles were asked. After doing so, the GPT considered it as a standard puzzle and responded accordingly.

2. Out of date information: While using one of the most famous LLM model chatgpt (model 3.5), you must have seen the response as shown in the figure. All the models that we used have the limitation that they only provide the response according to the data on which they trained. As the picture describes, it has the data only until October 2023, so it can’t provide the response after that date.

3. Generic Response: When we ask the LLM model about any specific domain, it first tries to provide a generic answer instead of a specific answer. As the picture suggests, I have asked about the leave policy of a particular company, but in response, it provides a generic answer to my question.

To tackle all the challenges caused by the LLM models, most of the companies use fine-tuning and RAG for solving these issues. Our main focus in this blog is on RAG, as it’s an RAG series, but we also see an overview of pre-training and the comparison of both RAG and fine-tuning.
What is RAG and why do we need it?
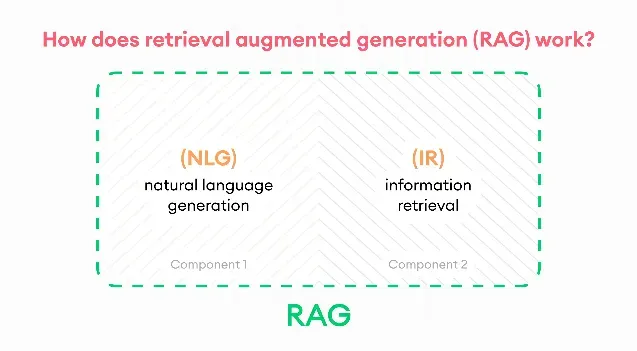
RAG is like an open book exam, as in an open book exam a student first finds the relevant information from the book and then uses that information to write its answer; similarly, RAG first extracts relevant information from a large corpus and then uses that context to generate the response.
So we can say that RAG is a technique that combines the power of information retrieval and text generation.
Let’s see with an example to understand it better: a person writing a blog first gather information about the relevant topic and then use it to write the blog. This is the same case in RAG, as the retriever part first extracts the appropriate context, and the generator uses it to generate the answer.
 credit: https://www.superannotate.com/blog/rag-explained
credit: https://www.superannotate.com/blog/rag-explained
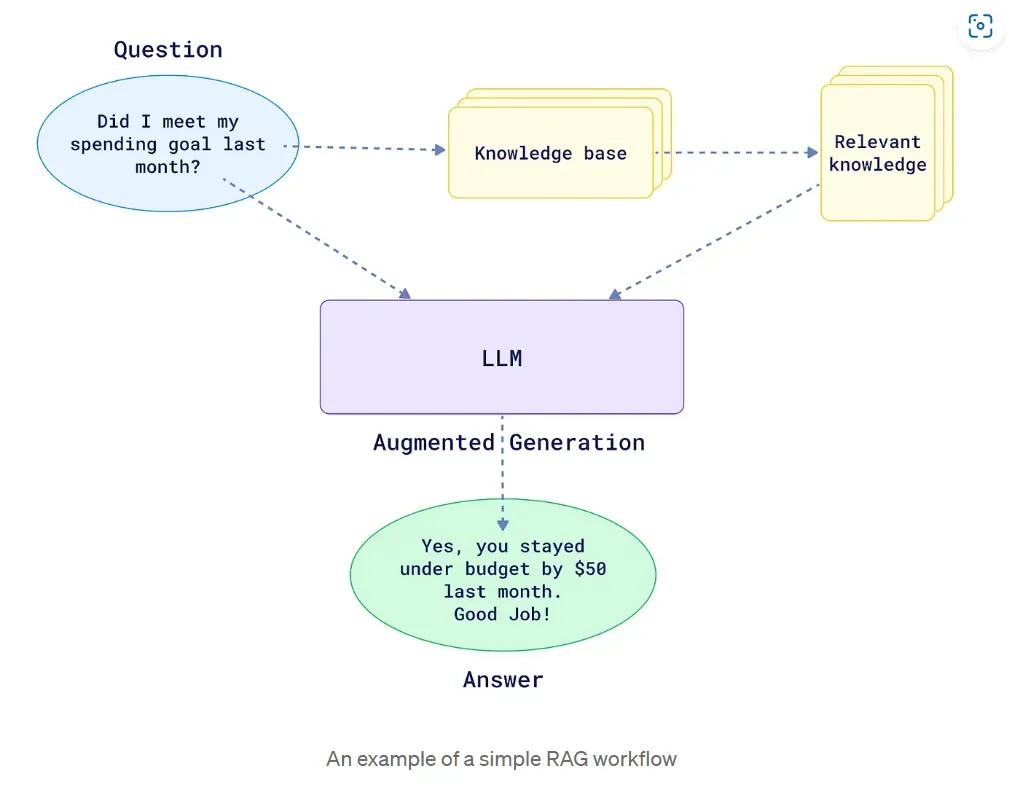
Basic Architecture to understand RAG working
Let us understand the architecture of the RAG in the below picture. As we can see in the picture, a question was asked first, which goes to the knowledge base to retrieve relevant information about the query, and after getting the relevant knowledge from the knowledge base, along with the query, that context is also passed to LLM to generate the response.
 credit: https://medium.com/@nikita04/what-is-rag-retrieval-augmented-generation-7875ce0de5b1
credit: https://medium.com/@nikita04/what-is-rag-retrieval-augmented-generation-7875ce0de5b1
Fine-Tuning
In fine-tuning, we take the pre-trained model and adjust its parameters to make it more specialised in a specific domain by retraining on a smaller dataset. We can do fine-tuning by using:
- Pre-Trained Model
- Task Specific Data
- Layer Adjustment
Fine-Tuning vs. RAG
Fine tune is another approach for optimizing large language model performances. That is why there is always a topic of debate as to why we need RAG. We can simply use fine-tuning as it is also doing the same work as RAG (optimising the model performance) and also performing domain related tasks, and we see the difference between fine-tuning and RAG in the below table.
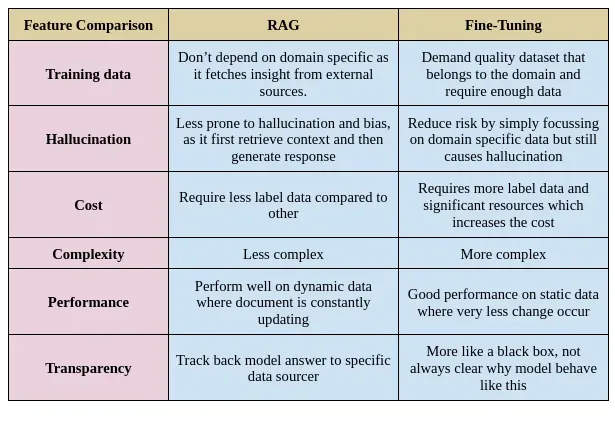
Comparison between RAG and Fine-Tuning
Takeaways from table
- In fine-tuning, we need a large amount of data, whereas in RAG there is no such requirement for external data.
- In fine-tuning, the previous weight is updated, but in RAG there are no changes in the weights that have been used.
Conclusion
In this blog, we explore the challenges faced by large language models (LLMs) and there potential solutions such as Retrieval-Augmented Generation (RAG) and fine-tuning. Both RAG and fine-tuning offer distinct advantages and are suited to different use cases. However, our focus will be on providing an in-depth analysis of RAG in upcoming blogs.